
Discover
Introduction to our GraphQL API
Why make the switch to GraphQL?
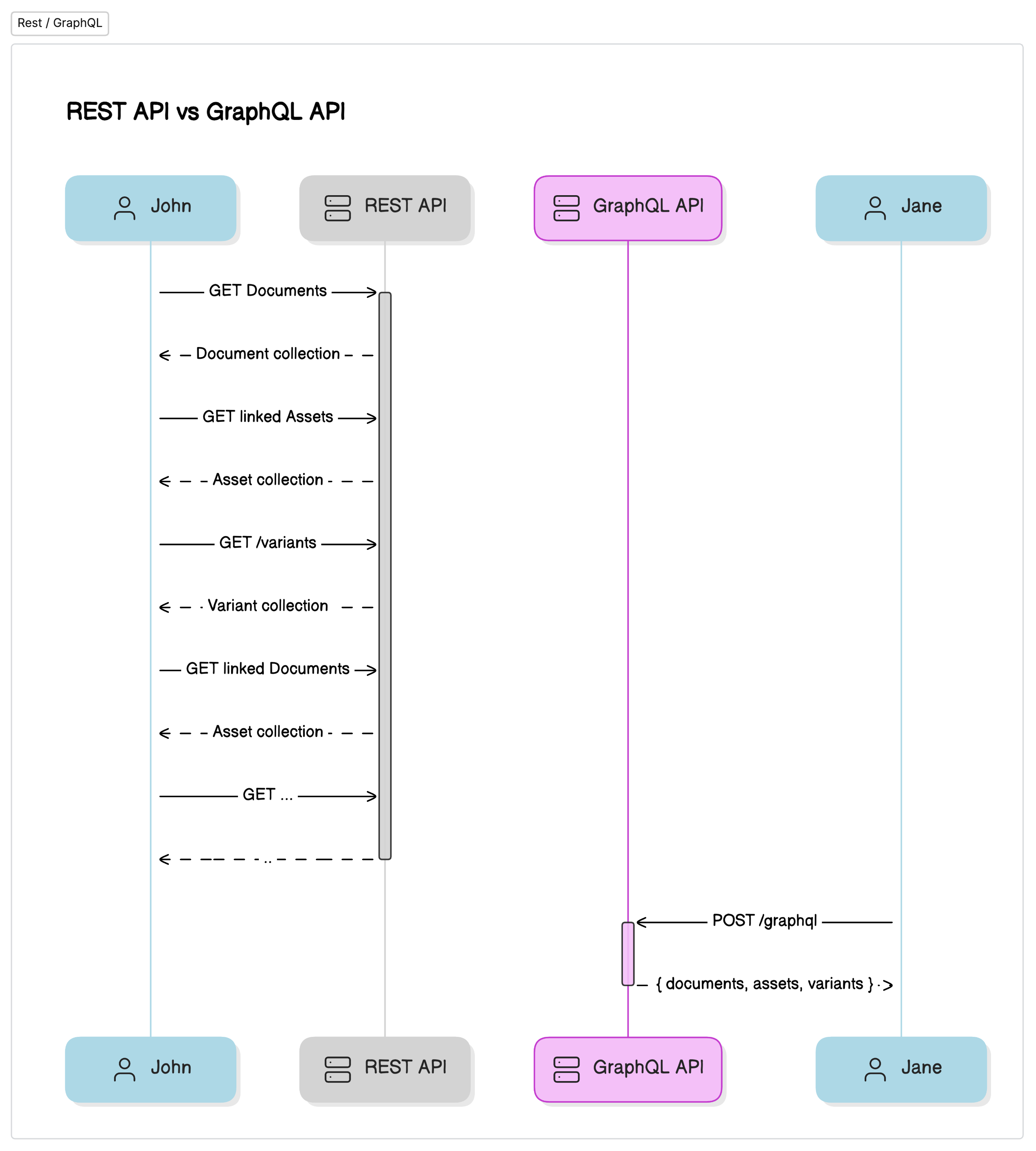
GraphQL is a game-changer in the world of APIs, overcoming the limitations of traditional architectures such as REST.
Traditional API architectures, like REST, often come with limitations in terms of flexibility and efficiency. REST relies on fixed endpoints, which can require multiple requests to gather all the necessary data. This can lead to over-fetching or under-fetching of data, resulting in unnecessary network overhead and inefficient use of resources, along with inflexible server responses.
GraphQL fundamentally changes this paradigm. It allows clients to specify exactly what data they need, providing a solution to the issues of over-fetching and under-fetching. As a result, developers can optimize bandwidth usage and reduce latency, enhancing the overall performance of the application.
Benefits for Developers
By introducing GraphQL into our system, we aim to offer a more flexible and efficient way to access data. Here are some specific benefits for developers:
- Customizable Queries: With GraphQL, you can request precisely the structure you need, avoiding the reception of unnecessary data and simplifying client-side processing.
- Reduced Network Requests: GraphQL allows the retrieval of multiple related resources in a single query, eliminating the need for multiple network calls and reducing server load.
- Strong Typing and Introspection: The strongly typed nature of GraphQL and its introspective capabilities facilitate self-documentation and query validation, enhancing code robustness and speeding up development.
Tool overview
This GraphQL PIM API is an advanced tool designed for efficient data extraction and management. It leverages a sophisticated caching system that works in tandem with our existing REST API. Whenever changes occur in PIM resources, the GraphQL API automatically updates its data cache in real-time.
Delay
Please note that the data available in GraphQL results may have a delay in terms of freshness.
This is due to the management of the API cache, which is essential to the ultra-fast response time you will get.
One of the key strengths of GraphQL is its ability to query multiple resources in parallel.
This feature significantly speeds up the retrieval of large volumes of information, making data fetching more efficient and reducing the time needed to obtain comprehensive datasets.
This API only supports read operations
This API is designed exclusively for fetching data and cannot be used for creating, updating or deleting resources.
Using the tool
Activation
To use the GraphQL API, you must submit a request via chat.
Please be aware that the GraphQL API will create a new webhook listener on your PIM. This system webhook is automatically managed on our end.
Authentication and security
The GraphQL API is equipped with robust security protocols to ensure data integrity and confidentiality. Access to its functionalities requires an API token, which can be obtained from your PIM.
To retrieve your API token, go to “Administration”, then “API Token” in your PIM interface.
Read Access Token
Since the GraphQL API is designed for read-only access, you can (and should) simply use your Read Access Token.
When making requests to the GraphQL API, it’s crucial to configure your HTTP request headers properly. Use the following template for your headers:
{
"instance": "<your-instance-name>",
"authorization": "Bearer <your-api-token>"
}Ensure to replace <your-instance-name> and <your-api-token> with the information corresponding to your configuration.
This version maintains clarity and provides essential instructions for developers on securing access to the GraphQL API and configuring their HTTP requests.
Access URL
You can access the Graphql API using the following address: https://graphql.quable.io/graphql
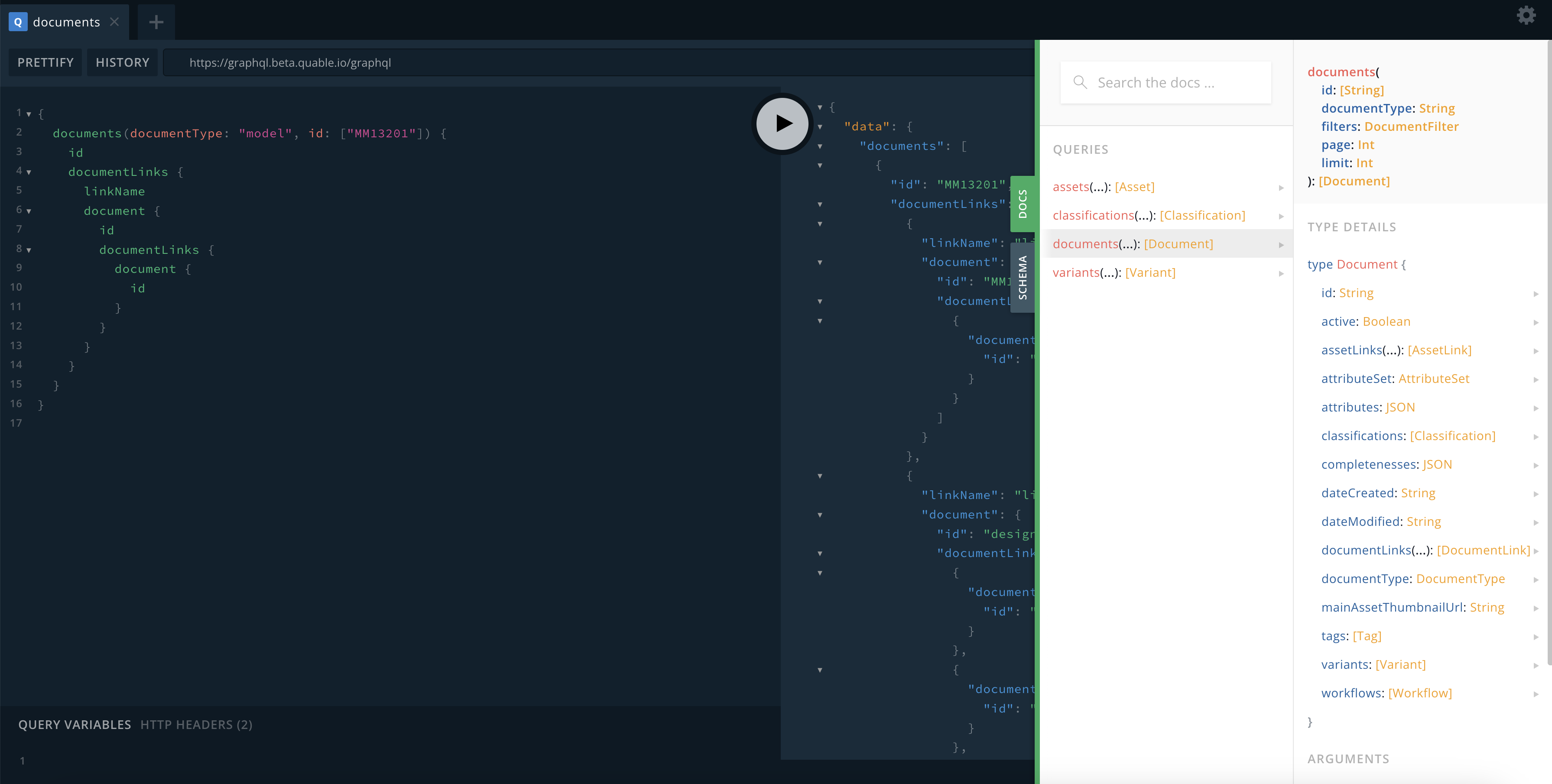
Schema description
Use your token to see the schema
Please note that the GraphQL API schema is available only if your credentials are validated. Please refer to "Authentication and security" and then you will be able to show the docs & schema panels.
Our GraphQL schema includes four primary entities: Document, Asset, Classification, and Variant.
You can query any of these entities to access their associated resources. The following schema shows the relationships between these entities, highlighting how they are linked in the PIM.
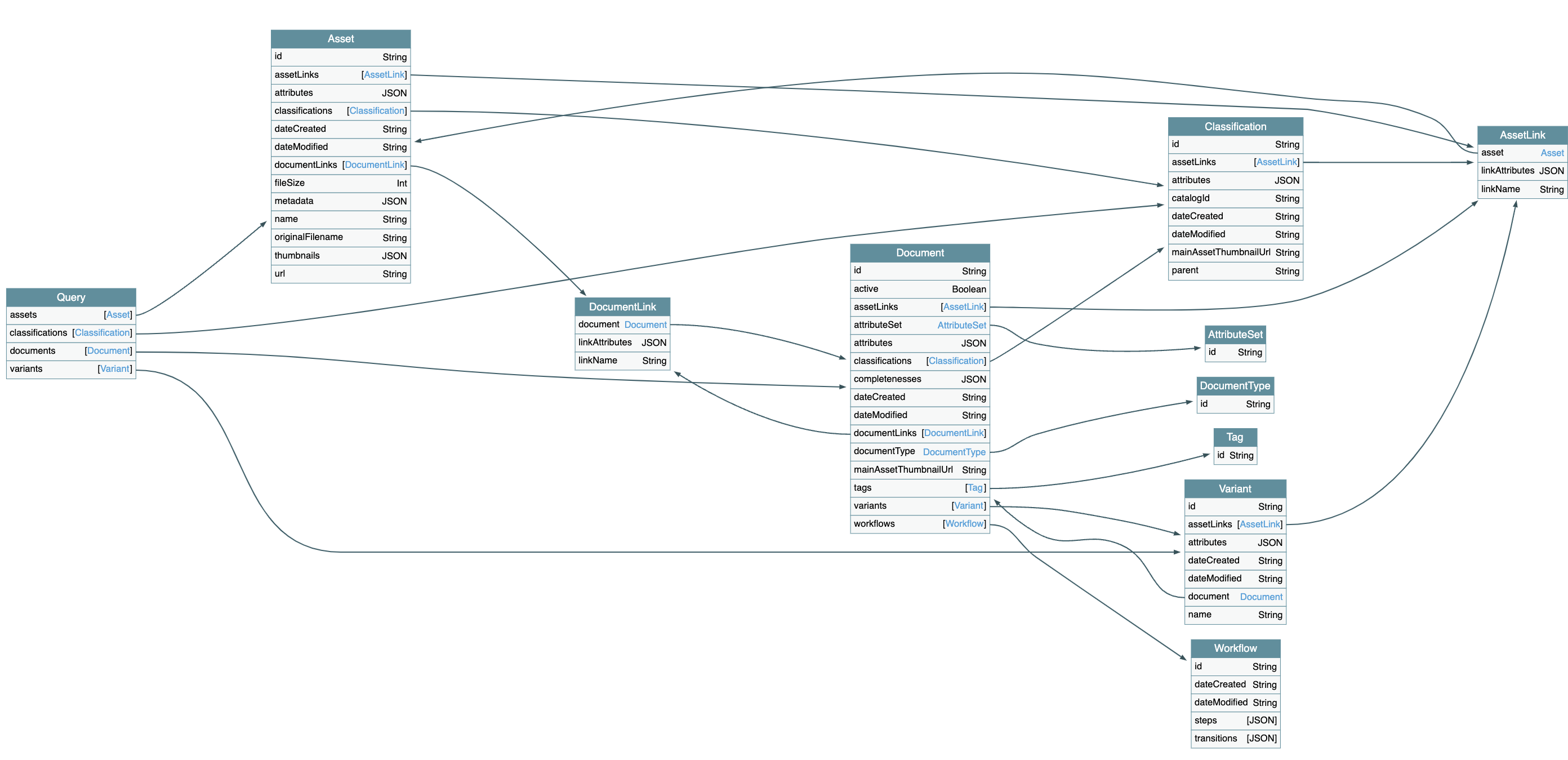
While accessing the GraphQL playground you can download schema as a JSON or SDL file.
Example
The following query example will retrieve multiple documents, including all related documents through the link "link_reference_color", their classifications, images, variants and the images of these variants.
query {
documents {
id
attributes
documentLinks(linkNames: ["link_reference_color"]) {
document {
id
}
}
classifications {
id
catalogId
}
variants {
id
attributes
assetLinks {
asset {
id
}
}
}
assetLinks {
asset {
assetLinks {
asset {
id
}
}
}
}
}
}Filters
Our GraphQL API includes filters to help you to control the quantity of data you receive. You can filter resources by their codes using the id argument, with a maximum of 50 codes.
Additionally, a DocumentFilter argument is available for documents and linked documents:
input DocumentFilter {
tags: [String]
workflowStep: [String]
completeness: CompletenessFilter
dateCreated: DateFilter
dateModified: DateFilter
}This DocumentFilter lets you refine your search for documents based on several criteria:
- tags : Filters documents by one or more tags, handling multiple tags as a logical OR.
- workflowStep : Filters documents by one or more workflow steps, also handling multiples as a logical OR.
- completeness : Uses a CompletenessFilter to assess the completeness of information in documents, requiring a code, locale code, an operator, and a value.
- dateCreated and dateModified : A DateFilter that lets you filter documents by their creation or modification date, based on a specific operator and date.
These filters allow for precise control and querying of resources according to your specific needs.
API Cache and Limits
To ensure the stability and integrity of our system, we have implemented limits on our API.
Depth limit
The "depth limit" is a control mechanism used to manage query complexity and safeguard server performance by restricting how deeply nested the fields in a query can be.
Current depth limit: 6
Query depth examples
Example 1: Simple query
Depth: 1
Description: This query retrieves basic information with minimal nesting, staying well within the depth limit.query { documents { id attributes } }Example 2: Maximum depth
Depth: 6
Description: This query involves moderate nesting, reaching the maximum allowed depth.{ documents { id documentLinks { linkName document { id documentLinks { document { id variants { id } } } } } } }Example 3: Exceeding depth limit
Depth: 11
Description: This query exceeds the depth limit, demonstrating how deeply nested queries can become problematic.query { documents { id documentLinks { linkName document { id documentLinks { document { id documentLinks { document { id documentLinks { document { id } } } } } } } } } }
Cost limit
The "cost limit" is a mechanism used to manage the computational expense of processing GraphQL queries. It helps ensure that queries do not exceed a specified cost, which could otherwise lead to performance issues or excessive resource consumption.
Cost limit: Under a rolling 10-minute window, the maximum allowed cost is 6 million.
How the cost limit Works:
The cost of each query is determined by summing the weight of each resource returned by the query.
The base costs for different resources are as follows :
- Document : 20 units
- Asset : 10 units
- Classification : 5 units
- Variant : 10 units
Each response from the server includes the following headers:
- x-weight-limiting-cost: Indicates the cost of the query that was just processed. It allows clients to see how much computational weight their request has consumed.
- x-weight-limiting-remaining: Shows the remaining cost available for the current 10-minute window. It helps clients manage their query costs and avoid exceeding the limit.
Cost calculation example
Consider a query that returns the following resources:
- 50 roots documents and :
- for each document 10 Assets.
- for each document 10 linked documents
- for each linked documents, 5 Assets
- for each document 1 Classification
- for each document 20 Variants
Detailed calculation:
- 50 root documents: 50 × 20 = 1,000 units
- 10 assets for each root document: 50 × 10 × 10 = 5,000 units
- 10 linked documents for each root document : 50 × 10 x 20 = 10,000 units
- 5 assets per linked document: 50 x 10 x 5 x 20 = 25,000 units
- 1 classification per document: 50 × 1 x 5 = 250 units
- 20 variants for each root document: 50 × 20 × 10 = 10,000 units
Total Cost = 1,000 + 5,000 + 10,000 + 25,000 + 250 + 10,000 = 51,250 units
Thus, the total cost of the query that returns the specified set of resources is 51,250 units.
Good practices and recommendations
Use the ID filter in your GraphQL query : By specifying resource codes, you can retrieve information directly from memory, resulting much faster responses. When you don't specify resources codes, the request takes longer because it involves additional resources, especially to ensure proper pagination functionality.
{ documents(id: ["A", "B", "C", "D"]) { id attributes documentLinks { linkName document { id } } } }Use the linkCode to filter links : To avoid confusion with the all the links that a resource might have, you can specify the link codes to retrieve only those specific links.
{ documents { id attributes documentLinks(linkNames: ["link_to_childs"]) { linkName document { id } } } }Non rediscovering : To prevent malicious query cycles, a child resource discovered by a parent resource cannot rediscover its parent again. For example: Document A is linked to Document B.
For the following GraphQL query:
{ documents(id: ["A"]) { id documentLinks { linkName document { id documentLinks { document { id documentLinks { document { id } } } } } } } }One might expect a loop between A and B, but the query will break upon the discovery of B, preventing any potential loops.
Manage rate limit : For each GraphQL query, you receive information in the headers x-weight-limiting-cost and x-weight-limiting-remaining. These headers should be used efficiently to manage your rate limit effectively and avoid being blocked.