
#
The PIM Data Aggregator
--
--
--
--
Available in beta only
This is available in beta for now. Be aware that some performance issues might occur.
#
Introduction
Exporting data from a PIM can sometimes come present format compatibility issues with certain e-commerce solutions, requiring technical adjustments and sometimes a multiple queries to achieve a full product information aggregation (attributes, images, linked documents and classifications). To prevent these problems, we developed the PIM Data Aggregator (PDA), an additive layer that grafts onto our PIM to restructure and unify exported data in a unified JSON format. This way, the PDA improves efficiency and facilitates the integration process for developers.
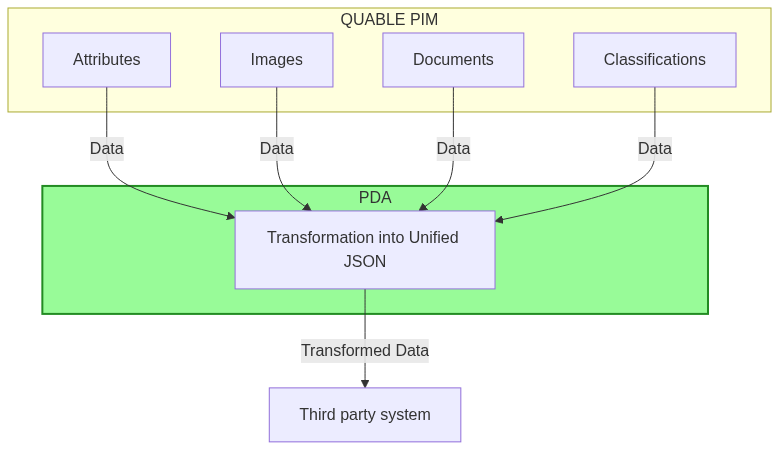
#
Tool overview
The PIM Data Aggregator is a powerful product data extraction tool. It interfaces seamlessly with our PIM to extract precise data according to a specific query structure. The major advantages of this tool are :
- Product information aggregation : The PDA collects all data relating to a product, including its attributes, classifications and digital resources (assets). It goes even further, integrating associated documents for a complete view.
- Multilevel information retrieval : The tool is designed to extract data in a structured way, up to three levels. On the first level, it assembles data on selected products. The second level gathers data on products linked to these products. The third level extends the retrieval to products associated with those on the second level, providing a complete and detailed overview.
Currently, PDA works in a top-down way, retrieving information from the main document to its child documents. You will not be able to go from a child document to its parent for the time being.

- Data filtering : With the PIM Data Aggregator, you have the flexibility to select and extract only the desired documents from your PIM. It offers advanced filtering options based on data completeness, workflow steps and specific catalogs, ensuring that you get precisely the data you need for your operations.
#
Authentication and security
The PDA (PIM Data Aggregator) incorporates robust security protocols to ensure data integrity and confidentiality. Access to its functionalities is conditional on the use of an API token, which you can obtain from your PIM.
To retrieve your API token, go to "Administration", then "API Token" in your PIM interface.
When initiating requests to the PDA, it's essential to configure your HTTP request headers correctly. Here's the template to follow for your headers:
{
"instance": "<your-instance-name>",
"authorization": "Bearer <your-api-token>"
}Ensure to replace <your-instance-name> and <your-api-token> with the information corresponding to your configuration.
Only full access tokens can trigger data extraction processes.
#
Using the tool
#
API URL
You can access the PDA using the following address: https://pda.quable.io
#
Payload description
To initiate a request to extract product information, you need to provide a payload. This must define not only the elements you wish to obtain, but also the depth at which the extraction is to be performed.
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "link_type_model_reference",
"secondLevelAssetLink": [
"article_images_media",
"link_type_model_reference_packshot"
],
"thirdLevelLink": "__variants__",
"thirdLevelAssetLink": ["sku_images_media"],
"filters": {
"documentIds": [],
"completeness": {
"code": "completeness_shopify",
"operator": ">=",
"value": 0.9
},
"workflow": {
"code": "workflow_enrichissement",
"step": "APPROVED"
},
"catalog": "SHOPIFY_WINTER_2022"
},
"localeCode": "fr_FR"
}documentType (string):This parameter defines the type of document you wish to export.
documentAssetLink (array): List of image link codes associated with the specified document type.
secondLevelLink (string): To obtain documents linked on two levels, this parameter must be filled in with the name of the target document link.
secondLevelAssetLink (array) : List of image link codes associated with the target document of the link specified in
secondLevelLink.thirdLevelLink (string) : To get documents linked on three levels, this parameter must be filled in with the name of the target document link.
thirdLevelAssetLink (array) : This list contains the image link codes associated with the target document of the link specified in
thirdLevelLink.filters (object) : Define filters for data extraction
- documentIds (array) : This filter lets you specify a list of document codes you wish to export.
- completeness (object) : You can use this filter to retrieve documents according to their completeness in the selected language.
- code (string): The code of completeness.
- operator (string): The comparison operator, with the following possible values: ==, <, <=, >, >=.
- value (int): The percentage completeness value, which must be between 0 (0%) and 1 (100%).
- workflow (array) : You can filter data by workflow code and workflow step.
- code (string) :Workflow code.
- step (string) : The workflow stage.
- catalog (string) : This filter allows you to restrict results according to a specific product catalog.
localeCode (string) : This parameter specifies the language in which you wish to retrieve data. The value must be the locale code.
To export document variants, use the keyword
__variants__as the link code.
In the payload, the secondLevelLink and thirdLevelLink attributes are used to define the depth of data extraction. More precisely:
- If both attributes,
secondLevelLinkandthirdLevelLink, are present, extraction takes place on three levels. - If only the
secondLevelLinkattribute is specified, extraction is limited to two levels. - If both attributes,
secondLevelLinkandthirdLevelLink, are absent, extraction is performed on a single level.
#
Endpoints description
#
a) Operation
This endpoint is designed to initiate a complete retrieval operation asynchronously. Once the request has been validated, the API returns a unique identifier for the current operation. This identifier can be used to monitor the status of the operation and to retrieve the generated file once it has been completed.
#
Create an operation : POST /operation
Body payload:
{
"documentType": "modèle",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "lien_type_reference_modele",
"localeCode": "fr_FR"
}If all goes well, you'll get:
{
"id": "150e61ea-0b31-4aa9-9d5c-90ae8d11422a",
"operationUrl": "https://pda.quable.io/operation/150e61ea-0b31-4aa9-9d5c-90ae8d11422a",
"status": "Pending",
"message": "Your data export operation has just started. Check the progress on the link provided."
}
#
Get an operation : GET /operation/<id-operation>
If your operation exists, you get:
{
"id": "66b150a1-6491-49f8-a8aa-325506577646",
"instance": "shopify-review",
"status": "In Progress",
"detail": null,
"progress": 75,
"createdAt": "2023-11-09T06:33:21.991Z",
"updatedAt": "2023-11-09T06:34:38.490Z",
"file": null
}
#
Download an operation result : GET /operation/<id-operation>/download
If your operation has been successful and your file is still valid, you will be able to download a zip file containing a JSONLine file.
About JSON Lines
JSON Lines, also known as "line-feed JSON", is a useful format for storing structured data that can be managed line by line. Each line contains all the information about a document, which is very advantageous when working with large volumes of data, as you process one line at a time without overloading your memory.
#
Cancel an operation: PUT /operation/<id-operation>/cancel
You can also cancel an operation if it is taking too long and you wish to start a new one.
#
b) Query
This endpoint lets you retrieve data quickly and synchronously, but has a limit of 30 documents that you can retrieve per request. It can be particularly useful when you need to quickly obtain information on a small number of documents.
You'll use the same payload described above. But here, the documentIds filter is mandatory. To extract information, simply use the POST method with the /query endpoint.
Body payload:
{
"documentType": "modèle",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "lien_type_reference_modele",
"localeCode": "fr_FR",
"filters": {
"documentIds": ["DA10668000"]
}
}In response, you receive a JSON array containing the requested elements:
{
"id": "DA10668000",
"attributes": {
"web_ip": [
{
"code": "web_ip44",
"label": "IP44"
}
],
"web_name": "BAGUE CABOCHON",
"web_google_shopping_category": "Apparel & Accessories > Jewelry > Rings"
},
"attributeSet": null,
"classifications": ["classification_FANBAC"],
"documentLinks": [
{
"id": "DA10668003",
"attributes": {
"web_ip": [
{
"code": "web_ip42",
"label": "IP42"
}
],
"web_name": "BAGUE CABOCHON GREEN"
},
"assets": {
"article_images_media": [],
"link_type_packshot": [
{
"id": "0f176f68-438b-44eb-a0cc-front",
"url": "https://cdn.quable.com/shopify-review/0f176f68-438b-44eb-a0cc-front/original/cabochon-ring-collection.jpg",
"name": "cabochon-ring-collection.jpg",
"attributes": {
"asset_title": "cabochon green 52",
"asset_date": "2023-10-18 00:00:00"
}
}
]
},
"attributeSet": null,
"classifications": ["classification_FANBAC"]
}
],
"assets": {
"article_images_media": [
{
"id": "5bfacf6e-5384-4dff-8154-front",
"url": "https://cdn.quable.com/shopify-review/5bfacf6e-5384-4dff-8154-front/original/10667800-cabochon-ring2.jpg",
"name": "10667800-cabochon-ring2.jpg",
"attributes": {
"asset_title": "Bag",
"asset_date": "2023-10-01 00:00:00"
}
}
]
}
}
#
API Cache and Limits
To avoid overloading and prevent abuse of our tool, we've introduced a caching system for the /operation endpoint. This means that if you send the same retrieval request several times within 10 minutes, you'll get the same result as on the first request. This also means you can retrieve data much more quickly.
We've also implemented API usage limits on the /query endpoint, which prevent you from making more than one request per second.
#
Integration and libraries
The PDA can also be used with the quable-pim-js.
import { QuablePimClient } from "@quable/quable-pim-js";
const client = new QuablePimClient({
instanceName: "<instance-name>",
apiKey: "<api-key>",
});
const payload = {
documentType: "product",
documentAssetLink: ["article_images_media"],
secondLevelLink: "link_type_link_product",
secondLevelAssetLink: ["article_images_media"],
thirdLevelLink: "__variants__",
thirdLevelAssetLink: ["sku_images_media"],
documentIds: ["CODE_8397340377410"],
localeCode: "fr_FR",
filters: {},
};
const data = await client.PimDataAggregator.Query.getData(payload);
#
Use cases
Data extraction with the PDA depends on your PIM's data model, which can lead to the following use cases:
- You want to extract a data model on a single level:
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"localeCode": "fr_FR"
}- You want to extract a 2-level data model, including documents and variants.
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "__variants__",
"secondLevelAssetLink": ["sku_images_media"],
"localeCode": "fr_FR"
}- You want to extract a 2-level data model, comprising documents and their associated documents.
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "link_type_model_reference",
"secondLevelAssetLink": [
"article_images_media",
"link_type_model_reference_packshot"
],
"localeCode": "fr_FR"
}- You want to extract a 3-level data model, comprising documents, their associated documents and the variants associated with them.
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "link_type_model_reference",
"secondLevelAssetLink": [
"article_images_media",
"link_type_model_reference_packshot"
],
"thirdLevelLink": "__variants__",
"thirdLevelAssetLink": ["sku_images_media"],
"localeCode": "fr_FR"
}- You want to extract a 3-level data model, comprising documents, their associated documents and other documents associated with them.
{
"documentType": "model",
"documentAssetLink": ["article_images_media"],
"secondLevelLink": "link_type_model_reference",
"secondLevelAssetLink": ["link_type_model_reference_packshot"],
"thirdLevelLink": "link_type_model_reference_accessoire",
"thirdLevelAssetLink": ["link_type_accessoire_packshot"],
"localeCode": "fr_FR"
}
#
Good practices and recommendations
If you need to retrieve more than 30 products, we strongly recommend you use the /operation endpoint, as it is better suited to managing large quantities of data.
The PDA is an essential tool for setting up connectors, as it enables you to obtain synchronizations in near real time. So, when you receive a notification of a document update in the PIM, you can make a call to /query to get all the information on that product in a consolidated way.
When working with the /operation endpoint, it's important not to load your entire JSONLine file into memory, as this can consume a lot of resources and paralyze your system. Instead, you can read it line by line or block by block and apply the necessary actions each time.
#
Ressources
You can find out more about the JSON Lines format at JSON Lines.
Quable documentation is available at Quable Documentation.
More information on the Quable PIM Javascript package can be found at NPM.